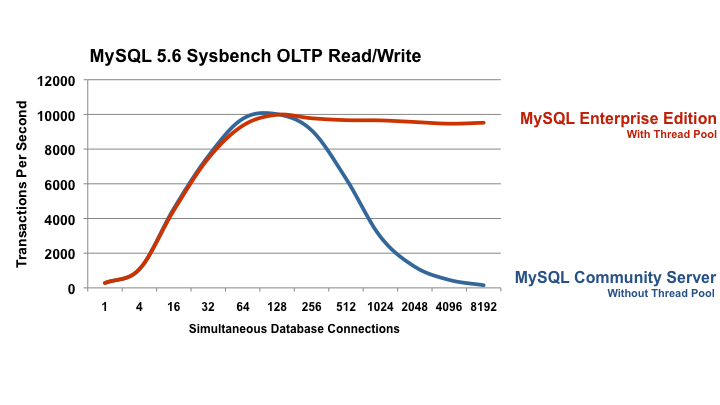
Not only are they related, the relation between them holds big part of the substance of ScaleBase, the technology I've been working on for the last 5 years...
Elasticity is the ability to grow or shrink in accordance to the demand.
The cloud makes it very easy to spin more machines, on demand and kill them a day after, pay by the hour, only for real usage. This alone offers fantastic elasticity. Remember that AWS's EC2 stands for "Elastic Compute Cloud".
Volatile/transient/stateless servers are easier to make elastic, AKA application servers, web servers. Just spin another same-image-server behind a round-robin load balancer would solve 80% of the problem.
Data is harder to "elastify".
- Data can be replicated across multiple identical servers behind the same round-robin load balancer, but data-replication multiplies data size (bad ROI) and cannot scale writes and updates to the data.
- The only way to scale data is to have it distributed across multiple non-identical servers.
New challenges:
- How would all data consumers (apps, tools) know where the data they look for resides?
- If all for every access they need data from several (or all) the servers, load will end-up multiplied rather than distributed. = no scalability.
- OK not all or most, but the minority of accesses do need data from several (or all) the servers. How this data can be found on all quickly and aggregated?
Challenge 1 is the simplest, just have an index expressing "I want to distribute my data by profile_id" and "put profiles 1-1000 on db1 and 1001-1500 on db2", and then force all data consumers check this index before every data access.
Challenges 2 and 3 are where data model kicks in. For NoSQLs, data model is a document, complete and self-contained, challenges 2 and 3 do not exist.
For SQL databases, a relational data model, takes challenges 2 and 3 to the extreme.
A carefully crafted data distribution policy and the ability to do real-time data aggregation are crucial for a successful scaling relational database.
In our profiles distribution example, identifying that "a profile" is actually a chunk of related data from 100 tables in a complex, multi-level, deep hierarchy - is a hard task to do.
ScaleBase Analysis Genie simplifies the authoring of a data distribution policy that makes sure that related data is stored together on the same server, solving challenge 2.
ScaleBase Controller employs multi-threaded massive parallel execution and advanced result aggregation, supporting all SQL aspects including support for GROUP BY, ORDER BY, HAVING, UNION, JOIN, SUBSELECT to solve challenge 3.
See here for more info: http://www.scalebase.com/products/product-architecture