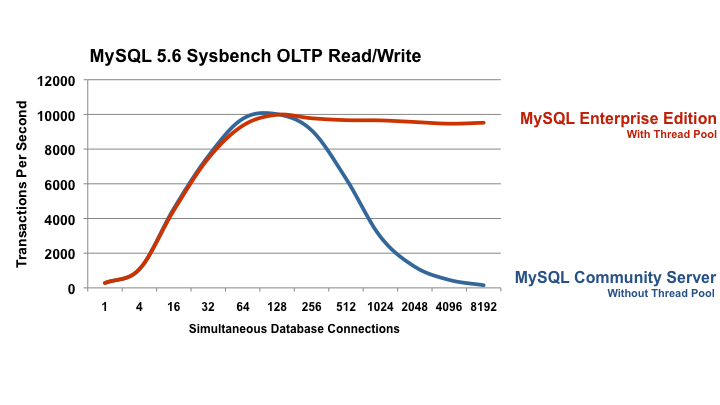
"Concurrency is the composition of independently executing processes, while Parallelism is the simultaneous execution of (possibly related) computations"As I wrote several times in the past, in OLTP, throughput is king, concurrency is the main thing that is put into the test.
Concurrency is where Facebook has a million "Like"s every second, each "Like" is independent, and they need to be processed concurrently.
Parallelism, is where few concurrent activities, say a few analytic reports run in Oracle Exadata, Vertica or GreenPlum. Every report is is sliced into many related computations that execute simultaneously.
Are these the same?
From 50,000 feet, we see many things running in the same time, in parallel, concurrently, maybe even distributed. But we need to be accurate, there is a huge difference, and it is in the source: how many "original" transactions we had to process? A million "Like"s vs. a few big analytic report. In both cases I see million operations coming out of them at the back, but:
In the "Like"s use case - those are the real transactions, concurrently running, distributed.
In the report use case - those are million pieces of the same initial single job.
Important! Not to be confused! Big difference! One is great for throughput scalability and one is not. More in my next post.